L’idée principale d’une régression logistique est d’adapter l’architecture de la régression linéaire pour analyser la relation entre une variable réponse ybinaire et une variable prédictive x (ou plusieurs variables prédictives). On représente cette relation avec l’expression y ~ x et un utilise la fonction glm(..., family = "binomial") en R. La représentation mathématique discutée en classe est donnée ci-dessous (régression logistique simple) :
\[logit(P) = \hat\beta_0 + \hat\beta_1x_{i_{1}}\]
11.1.1 La logique du modèle
On veut utiliser la même architecture de modèle1 utilisée pour les régressions linéaires déjà discutées dans le cours : une droite (changement constant)
Mais cela n’est pas compatible avec la notion de probabilité, qui contraint les valeurs à l’intervalle [0,1]. En plus, la ligne de tendance représentant une probabilité est typiquement en forme de S (sigmoïde)
On pourrait utiliser les cotes (odds), qui sont linéaires et qui, par conséquent, génèrent une droite. Cependant, les odds sont asymétriques, comme discuté en classe
Solution : on utilise les logs de cotes (log-odds) = c’est le logit de la probabilité
Voici l’exemple discuté en classe (villes2.csv) :
La cote (les chances) d’être dans une ville francophone = 2.9
La cote (les chances) de n’être pas dans une ville francophone = 0.3
À partir du point central (1), on remarque que l’échelle en odds est très asymétrique :
Odds : linéaires mais asymétriques
Lorsqu’on transforme odds en log-odds, on arrive à une échelle symétrique dont le point central est toujours zéro :
Le log-odds d’être dans une ville francophone = 1.08
Le log-odds de n’être pas dans une ville francophone = -1.08
Log-odds : linéaires et symétriques
Donc, alors que les modèles linéaires donnent des coefficients dans l’unité originale (brute) de la variable de réponse, les modèles logistiques donnent des coefficients en log-odds. C’est la principale différence du modèle dans notre cours, vu que les modèles linéaires ont déjà été discutés.
NoteTableau de conversion
Voici un tableau adapté à partir de Garcia (2021) (p. 146) pour faciliter la conversion entre les unités discutées en classe. L’hypothèse nulle = \(\hat\beta = 0\), ce qui équivaut intuitivement à une probabilité de 50 %.
P
Odds
ln(odds) = \(\hat\beta\)
0.10
0.11
–2.20
0.20
0.25
–1.39
0.30
0.43
–0.85
0.40
0.67
–0.41
0.50
1.00
0.00
0.60
1.50
0.41
0.70
2.33
0.85
0.80
4.00
1.39
0.90
9.00
2.20
Donc, vous pouvez mémoriser les valeurs extrêmes, qui couvrent des probabilités allant de 10 % à 90 %.
Assurez-vous de réviser Larmarange (2023) (chap. 22) ou Garcia (2021) (chap. 7) pour bien comprendre la logique des régressions logistiques.
11.2 Un exemple
Voici l’exemple de la séance : francophone ~ note. On avait déjà examiné si une ville pourrait affecter les notes des apprenants : note ~ ville. C’était une régression linéaire, vu que la variable de réponse est continue. Maintenant, on vérifie si on peut prédire la ville où un apprenant a étudié à partir de sa note dans le même fichier (villes2.csv) en utilisant une régression logistique, vu que la variable de réponse est binaire. En fait, ce n’est pas la ville qui sera prédite : c’est la francophonie de la ville, vu qu’une régression logistique n’est pas capable de modéliser une réponse avec trois niveaux (ville), voilà pourquoi la dichotomisation est essentielle ici.
On utilise ici l’extension arm pour convertir facilement une valeur en log-odds en probabilité avec la fonction invlogit(). On commence avec la création de la variable binaire francophone avec la fonction if_else() et l’exploration visuelle des données. Veuillez noter que la nouvelle variable sera dichotomisée (0/1). Pour la figure, on utilise les langues comme valeurs, mais, dans les valeurs originales, cette variable est codée sous 0 ou 1.
Code
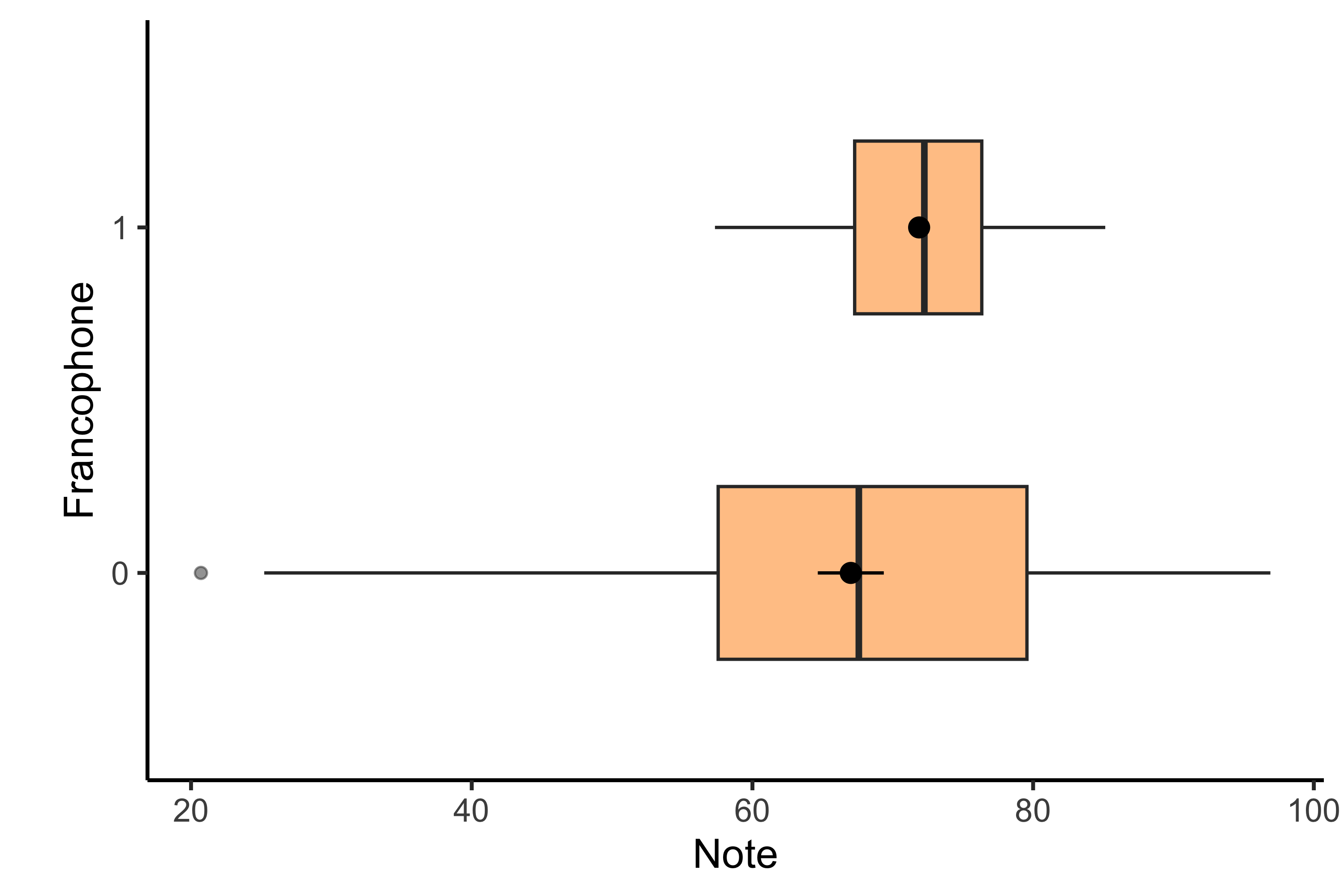
library(tidyverse)library(arm)# Importer les donnéesvilles =read_csv("donnees/villes2.csv")# Créer la nouvelle colonne : 0/1villes = villes |>mutate(francophone =if_else(ville =="Calgary", 0, 1))# Figureggplot(data = villes, aes(x = francophone |>as_factor(), y = note)) +geom_boxplot(fill ="darkorange", alpha =0.5, width =0.5) +stat_summary() +theme_classic(base_size =13) +labs(x ="\nLangue officielle de la ville",y ="Note") +scale_x_discrete(labels =c("0"="Anglais","1"="Français"))
Figure 11.1. L’influence de la langue de la ville sur les notes des apprenants
Bien que les boîtes soient superposées, si vous examinez la position des moyennes dans la figure, vous remarquerez un possible effet de la francophonie sur les notes dans la Fig. 11.1.2 Pour le confirmer, on exécute notre régression logistique en utilisant la fonction glm(). Notre modèle sera spécifié sous francophone ~ note. Observez la figure encore une fois : notre axe y contient notre variable prédictive. Jusqu’ici, l’axe y était toujours l’axe de la variable de réponse. Ici, étant donnée la nature binaire de la variable de réponse, on utilise souvent l’axe y pour des variables prédictives continues (s’il y en a). La Fig. 11.2 présente la version plus « traditionnelle » de la relation en question, où la variable de réponse est 0 et 1 dans l’axe y. Les deux options sont valides, mais la Fig. 11.1 est probablement plus commune dans les la littérature.
Figure 11.2. L’influence de la langue de la ville sur les notes des apprenants
Voici le rapport du modèle discuté en classe (Tableau 11.1).
Notre modèle confirme un effet significatif de la variable sur la variable (\(\hat\beta = 0,04\), IC 95 % = \([0,0094; 0,0076], p = 0,015\)). Ces résultats indiquent que, pour chaque augmentation de 10 points dans la note d’un apprenant, les log-odds d’être dans une ville francophone augmente de 0,4. Autrement dit, les chances d’être dans une ville francophone augmentent d’un facteur de 1,5.3
Code
library(sjPlot)mod1 =glm(francophone ~ note, data = villes, family ="binomial")tab_model(mod1, transform =NULL,string.pred ="Variables", string.ci ="IC 95 %",string.est ="Coefficients",string.p ="Valeur p")
Tableau 11.1. Régression logistique (coefficients en log-odds)
francophone
Variables
Coefficients
IC 95 %
Valeur p
(Intercept)
-2.18
-4.65 – 0.06
0.067
note
0.04
0.01 – 0.08
0.015
Observations
150
R2 Tjur
0.052
11.3 R² classique et R² de Tjur
Dans un modèle de régression linéaire classique (lm()), le coefficient de détermination (\(R^2\)) mesure la proportion de la variance totale de la variable de réponse expliquée par les prédicteurs du modèle. Il est défini comme :
\[
R^2 = 1 - \frac{\text{RSS}}{\text{TSS}}
\]
où RSS est la somme des carrés des résidus et TSS est la somme totale des carrés. Ce \(R^2\)) varie de 0 à 1 et a une interprétation intuitive : il indique le pourcentage de la variance de \(Y\) que le modèle explique.
En revanche, pour les modèles de type glm(family = "binomial"), où la variable dépendante est binaire (0 ou 1), le \(R^2\) classique n’est plus approprié, car la variance des résidus ne suit plus une loi normale avec variance constante. Pour évaluer l’ajustement dans ce contexte, plusieurs mesures de pseudo-\(R^2\) ont été proposées. Parmi celles-ci, le \(R^2\) de Tjur est particulièrement intuitif (Tjur 2009).
Le R² de Tjur (ou coefficient de discrimination) est défini comme la différence entre :
la moyenne des probabilités prédites pour les observations où \(Y = 1\)
et la moyenne des probabilités prédites pour les observations où \(Y = 0\)
Formellement :
\[
R^2_{\text{Tjur}} = \bar{p}_1 - \bar{p}_0
\]
Ce \(R^2\) mesure donc la capacité du modèle à séparer les deux classes. Une valeur de 1 indique une séparation parfaite, tandis qu’une valeur proche de 0 indique une absence de pouvoir discriminant.
11.3.1 Exemple simple
Supposons qu’un modèle de régression logistique prédise les probabilités suivantes :
Vrai Y
Probabilité prédite
1
0,85
1
0,90
0
0,20
0
0,15
On calcule :
\(\bar{p}_1 = (0,85 + 0,90) / 2 = 0,875\)
\(\bar{p}_0 = (0,20 + 0,15) / 2 = 0,175\)
Ainsi :
\[
R^2_{\text{Tjur}} = 0,875 - 0,175 = 0,70
\]
Ce résultat indique que le modèle sépare assez bien les deux classes.
11.4 Prédictions
Quel est l’effet de note sur francophone? La question ici est vraiment « Quelle est la probabilité qu’une ville soit francophone étant donnée la note moyenne d’un apprenant qui étudie dans cette ville? ». Autrement dit, on veut analyser \(P(francophone = 1 | note)\). Le modèle nous donne un effet positif de note : \(\hat\beta=\) 0.04 (log-odds). Cela veut dire qu’une augmentation d’un point dans la note augmente les chances que la ville est francophone d’un facteur de 1.042 (exp(beta) = 1.042), c’est-à-dire une augmentation de 4.2 %. On parle des chances (odds) et de log-odds parce que les deux nous donnent une droite, c’est-à-dire un changement constant qui nous permet d’évaluer n’importe quel effet pour n’importe quelle valeur de variable prédictive qu’on choisit.
Si vous voulez parler des probabilités, la suggestion est de prendre des valeurs spécifiques pour la variable note et de vérifier les changements des probabilités. On peut utiliser la fonction invlogit() de l’extension arm :
Le code ci-dessus montre comment calculer manuellement P(francophone=1|note=79). Cependant, il y a une facon plus automatisée d’accomplir la tâche, heureusement. La fonction predict() nous permet de prédire la probabilité de n’importe quelle note ici à partir d’un modèle (linéaire ou logistique) :
C’est une fonction très importante : on peut calculer plusieurs probabilités rapidement. Attention : il faut utiliser toutes les variables prédictives dans le modèle en question. Ici, on n’a qu’une variable. Donc, l’argument newdata contient un tableau très simple. Voyons comment calculer les probabilités pour plusieurs notes :
Notez que les différences entre chaque probabilité ne sont pas constantes. Voilà pourquoi on évite de parler des probabilités de manière absolue : c’est toujours un question de comparaison, vu que la ligne des probabilités n’est pas droite.
Pratique
Question 1. Chargez le script qui nettoie les données du fichier questionnaire2.csv et créez une figure appropriée.
Question 2. Exécutez une régression logistique pour analyser l’effet de la variable langues sur la précision des participants.
Question 3. Interprétez vos résultats en détail.
Question 4. La variable geo a-t-elle un effet sur la précision des réponses tout en tenant compte de l’effet potentiel de langues?
Question 5. Quelle est la probabilité qu’un participant répondra correctement si il n’aime pas la géographie? Considérez deux scénarios : il parle d’autres langues et il ne parle pas d’autres langues.
Garcia, Guilherme Duarte. 2021. Data visualization and analysis in second language research. New York, NY: Routledge.
Larmarange, Joseph. 2023. Introduction à l’analyse d’enquêtes avec R et RStudio.
Tjur, Tue. 2009. « Coefficients of Determination in Logistic Regression Models—A New Proposal: The Coefficient of Discrimination ». The American Statistician 63 (4): 366‑72. http://www.jstor.org/stable/25652317.
Il s’agit d’une famille de modèles statistiques : les modèles linéaires généralisés (Generalized Linear Models), ce qui comprend les régressions linéaires, logistiques, poissons, etc.↩︎
Notez aussi que les tailles des boîtes sont très différentes, ce qui indique une différence dans les variances des groupes. Bien que ce type de situation soit un problème pour les régressions linéaires, qui supposent que les groupes ont la même variance, ce n’est pas un problème pour les régressions logistiques. Cette supposition est fréquemment incorrecte.↩︎
C’est le résultat de exp(0.04^10). La fonction exp() nous donne le rapport des cotes (odds-ratio). Le 10 ici indique la quantité de points qu’on veut utiliser dans le calcul. Pour calculer le rapport des cotes d’un seul point, on utiliserait exp(0.04). Si vous utilisez la fonction tab_model() de l’extension sjPlot, les coefficients seront affichés en odds-ratio, pas en log-odds. Consultez le code ci-dessous pour vérifier comment afficher les coefficients en log-odds.↩︎