Code
library(tidyverse)
villes = read_csv("donnees/villes.csv")
ggplot(data = villes, aes(x = ville,
y = note)) +
stat_summary() +
theme_minimal(base_size = 15) +
labs(x = "Ville",
y = "Note")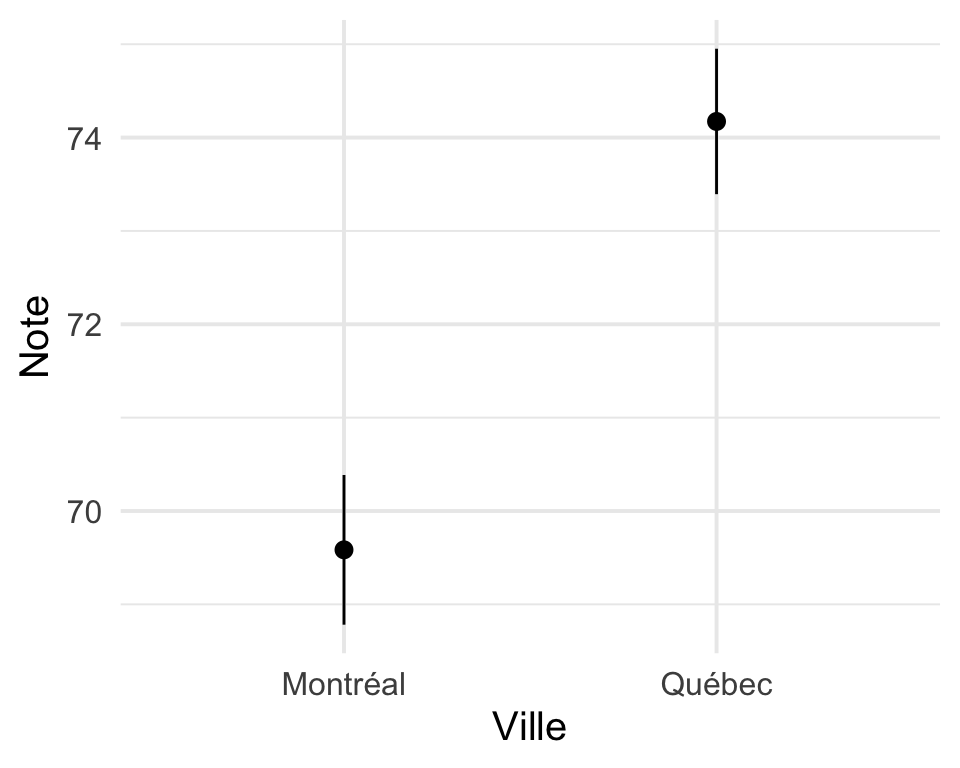
L’analyse de variance (ANOVA) n’est en réalité qu’un cas particulier de la régression linéaire. Dans une ANOVA classique, on analyse l’effet d’une variable catégorielle sur une variable continue en comparant les moyennes des groupes. Toutefois, ce modèle peut être reformulé comme une régression linéaire où les niveaux de la variable catégorielle sont encodés à l’aide de variables indicatrices. Ainsi, une ANOVA à un facteur n’est rien d’autre qu’un modèle de régression linéaire où les prédicteurs sont exclusivement catégoriels. Dès lors, plutôt que de traiter l’ANOVA comme une approche distincte, il est plus logique de la considérer comme un cas particulier du modèle linéaire général.
Privilégier un modèle de régression linéaire complet plutôt qu’une simple ANOVA présente plusieurs avantages. Par exemple, la régression permet d’incorporer simultanément des prédicteurs continus et catégoriels, offrant ainsi une plus grande flexibilité dans la modélisation des relations entre variables. Ensuite, la régression permet d’étudier les interactions et d’intégrer des covariables, ce qui est essentiel pour éviter les biais d’omission (bien que les interactions ne seront pas dans nos analyses). De plus, elle fournit des coefficients interprétables qui permettent d’évaluer l’effet précis de chaque variable, plutôt que de se limiter à de simples comparaisons de moyennes (dans une ANOVA, il faut calculer l’effet séparément). Enfin, la régression linéaire s’inscrit dans un cadre plus général qui englobe de nombreux autres modèles statistiques (modèles linéaires généralisés, modèles à effets mixtes, etc.), ce qui en fait un outil plus puissant et polyvalent pour l’analyse des données.
L’idée principale d’une régression linéaire est d’analyser la relation entre une variable de réponse y et une variable prédictive x. Naturellement, cette relation doit être linéaire pour que nos résultats soient fiables et précis. On représente cette relation avec l’expression y ~ x et on utilise la fonction lm() en R. La représentation mathématique est donnée ci-dessous :
\[\hat y_i = \hat\beta_0 + \hat\beta_1x_{i_{1}} + \hat{e}\]
« La réponse \(y_i\) est le résultat de la somme des variables + l’erreur (\(\hat{e}\)) ».
On peut ajouter n’importe combien de variables à notre modèle : y ~ x + w + z .... Donc, c’est facile d’examiner les effets de plusieurs variables prédictives sur la variable de réponse y. Dans la séance, on a commencé notre analyse avec le modèle suivant (villes.csv) :
mod1 = lm(note ~ ville, data = villes)
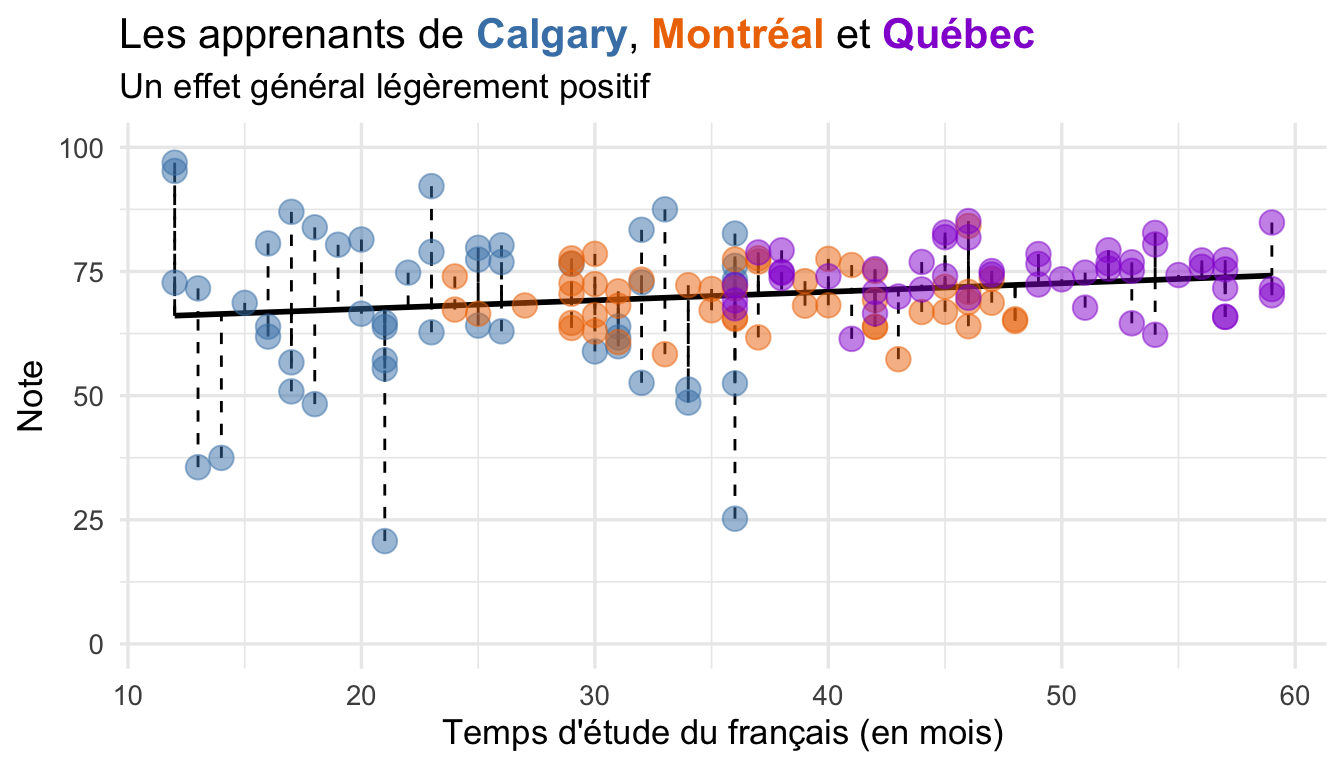
Ici, on estime l’effet de la variable ville sur la réponse (note). Effectivement, ce modèle compare les notes moyennes de Montréal et de Québec. L’hypothèse nulle est toujours la même : la différence réelle entre les deux villes est nulle (zéro). C’est toujours une bonne idée de visualiser les données avant d’exécuter un modèle.
library(tidyverse)
villes = read_csv("donnees/villes.csv")
ggplot(data = villes, aes(x = ville,
y = note)) +
stat_summary() +
theme_minimal(base_size = 15) +
labs(x = "Ville",
y = "Note")En examinant la Fig. 6.1, on constate que la moyenne du groupe de Québec est supérieure à celle du groupe de Montréal. Il faut maintenant vérifier cet effet statistiquement avec une régression linéaire (fonction lm()).
Normalement, on utilise la fonction summary() pour visualiser les résultats de nos modèles (cette fonction ne nous donne pas les intervalles de confiance). Par contre, la fonction tab_model() de l’extension sjPlot nous donne un résultat plus clair avec un tableau qui est déjà mis en forme et qui inclut les intervalles de confiance au niveau de 95 % :
library(sjPlot)
mod1 = lm(note ~ ville, data = villes)
tab_model(mod1,
title = "Tableau statistique
de la régression", dv.labels = "",
string.pred = "Variables",
string.ci = "IC 95 %",
string.est = "Coefficients",
string.p = "Valeur p")| Variables | Coefficients | IC 95 % | Valeur p |
| (Intercept) | 69.58 | 68.02 – 71.15 | <0.001 |
| ville [Québec] | 4.59 | 2.37 – 6.81 | <0.001 |
| Observations | 100 | ||
| R2 / R2 adjusted | 0.147 / 0.138 | ||
Le modèle nous donne les coefficients, c’est-à-dire nos bêtas (\(\hat\beta\)). Notre variable prédictive (ville) étant catégorielle, R choisit Montréal comme l’intercept (ordre alphabétique). Par conséquent, notre modèle peut être représenté par :
\[\hat y_i = \hat\beta_0 + \overbrace{\hat\beta_1x_{i_{1}}}^{\text{Québec}} + \hat{e}\] L’intercept est toujours la réponse prévue lorsque toutes les autres variables prédictives sont égales à zéro. Ici, on voit que :
Donc, on conclut que l’effet de ville est statistiquement significatif. Si on utilise la fonction summary() pour visualiser les résultats de notre modèle, on peut calculer les intervalles de confiance au niveau de 95 % séparément, qui seront normalement rapportés avec les effets \(\hat\beta\) et leurs valeurs \(p\) :
confint(mod1) 2.5 % 97.5 %
(Intercept) 68.01507 71.15253
villeQuébec 2.37048 6.80752Finalement, il faut noter que chaque valeur p représente un test statistique qui nous permet de rejeter ou non l’hypothèse nulle. Prenons l’intercept, représenté ici par Montréal. L’hypothèse nulle de notre bêta est que la note moyenne de Montréal est de zéro. Évidemment, on rejette cette hypothèse, vu que la note moyenne est de 69.58. Ensuite, l’hypothèse nulle pour Québec (notre slope) sera de zéro aussi, c’est-à-dire que la différence entre la note moyenne de Montréal et Québec est de zéro. On rejette cette hypothèse aussi.
Il est utile de comparer les résultats de notre régression ci-dessus à ceux d’une ANOVA équivalente. Voici une ANOVA simple, déjà discutée en classe, pour les mêmes données modélisées dans notre régression mod1.
une_anova = aov(note ~ ville, data = villes)
summary(une_anova) Df Sum Sq Mean Sq F value Pr(>F)
ville 1 526.5 526.5 16.85 8.38e-05 ***
Residuals 98 3062.0 31.2
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Veuillez noter que les résultats d’une ANOVA ne nous donne que les valeurs F et p. On peut simplement vérifier si l’hypothèse nulle serra rejetée ou non. Si vous voulez examiner où les différences se retrouvent, il faudra exécuter un test post-hoc, par exemple. Dans une régression traditionnelle, en revanche, on mets l’accent sur les effets de chaque variable analysée. Bien que les deux méthodes nous permettent de rejeter l’hypothèse nulle ici, les résultats de l’ANOVA sont beaucoup plus limités.
Comme d’habitude, révisez attentivement les questions et les solutions ci-dessous. Si vous avez des questions, utilisez le forum sur monPortail. Lisez les interprétations plusieurs fois pour vous assurer que vous comprenez bien les résultats de chaque régression/modèle.
Question 1. Une ville de plus. Dans un nouveau script, importez le fichier villes2.csv et explorez les différences entre les groupes par rapport à la variable ville. Créez une figure pour les variables ville et note. Exécutez un modèle linéaire avec ces variables. Interprétez les résultats. Répétez les étapes 3–6 avec les variables duree (temps d’étude du français) et note
Question 2. Une variable de plus. On peut avoir plusieurs variables prédictives : y ~ x + w + z .... Créez une figure pour note, ville et duree. Exécutez un modèle linéaire avec ses variables. Interprétez les résultats : nos conclusions changent-elles? Extra : reproduisez la figure dans la diapo de la séance 5.
Quand on ajoute plus d’une variable prédictive dans une régression, il s’agit d’une régression (linéaire) multiple. Essentiellement, ici on pose la question « lorsque la variable ville est considérée, est-ce que l’on observe un effet de la variable duree? » (et vice versa). C’est pourquoi il est important de considérer plusieurs variables à la fois : parfois, l’effet observé provient d’une autre variable! Notre modèle ici peut être représenté mathématiquement ainsi :
\[\overbrace{\hat\beta_0}^{\text{Calgary}} + \overbrace{\hat\beta_1X}^{\text{Montréal}} +\overbrace{\hat\beta_2X}^{\text{Québec}} + \overbrace{\hat\beta_3X}^{\text{temps d'étude}} + {\hat{e}}\]
L’avantage de créer la figure de la question 2 est que c’est plus facile de constater que l’effet de duree était apparent, mais il n’est pas réel une fois que l’on considère la variable ville aussi. La situation observée ici entre ville et duree est connue sous le nom de « paradoxe de Simpson ».
Une version plus avancée de la figure. Si vous aimez la visualisation de données, voici une option plus intéressante où on utilise les couleurs dans le titre pour signaler chaque groupe. On ne va pas examiner ce type de code dans le cours : c’est un « extra ». Le code ici utilise Markdown ainsi que HTML et CSS, mais vous n’avez pas besoin de le comprendre pour l’utiliser, naturellement. La police de la figure est différente aussi (Futura).
# Choisir quelques couleurs pour les villes et les nommer :
library(tidyverse)
villes = read_csv("donnees/villes2.csv")
couleurs = c("darkorange2", "darkviolet", "steelblue")
names(couleurs) = c("Montréal", "Québec", "Calgary")
# Créer le titre :
titre = glue::glue('Les apprenants de <span style="color:{couleurs["Calgary"]}">**Calgary**</span>,
<span style="color:{couleurs["Montréal"]}">**Montréal**</span> et
<span style="color:{couleurs["Québec"]}">**Québec**</span>')
ggplot(villes, aes(x = duree, y = note)) +
stat_smooth(method = "lm", color = "black") +
geom_point(size = 4, alpha = 0.5, aes(color = ville)) +
coord_cartesian(xlim = c(0, 60)) +
labs(x = "Temps d'étude du français (en mois)",
y = "Note",
color = "Ville:",
title = titre,
subtitle = "Un effet général légèrement positif") +
theme_minimal(base_size = 13) +
theme(plot.title = ggtext::element_markdown(),
legend.position = "none") +
coord_cartesian(ylim = c(0, 100)) +
theme(plot.title = ggtext::element_markdown(),
plot.subtitle = ggtext::element_markdown()) +
scale_color_manual(values = couleurs)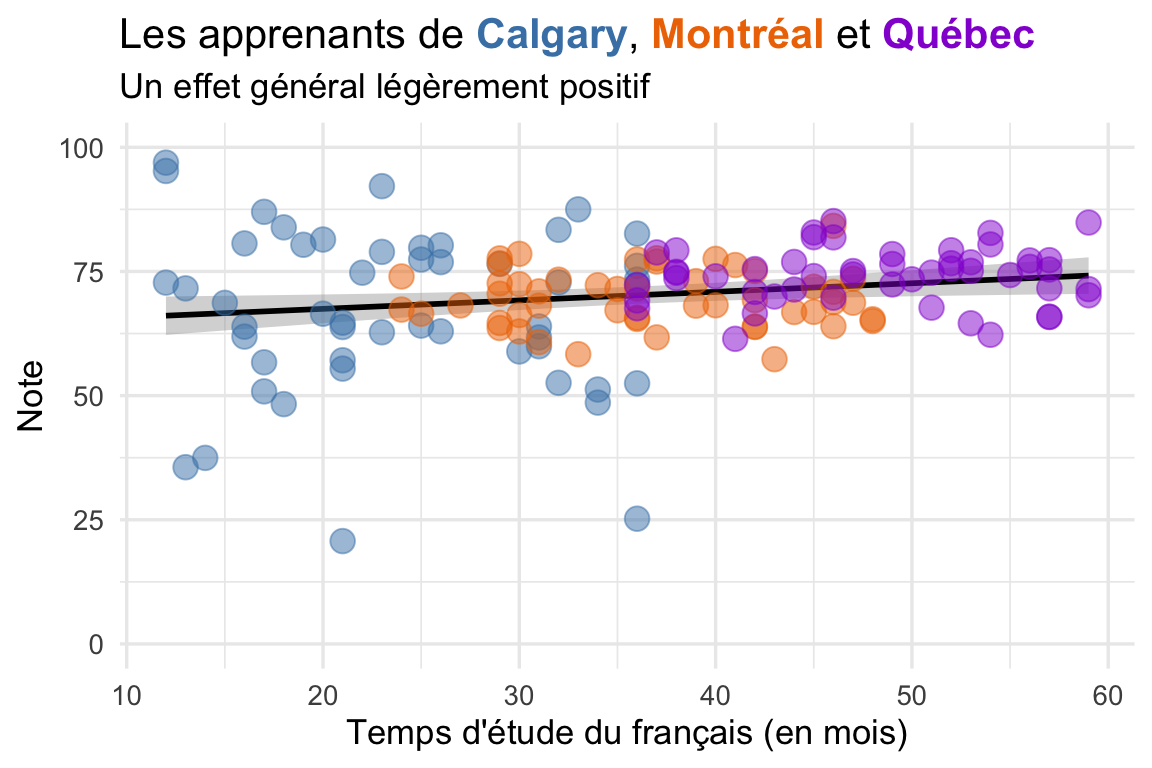
ville représentée par trois couleurs
L’erreur standard est l’écart type de la distribution d’échantillonnage. Il s’agit un concept très abstrait, mais ce n’est pas difficile de le vérifier en simulant des données en R.
Imaginez les étapes suivantes :
L’écart type de ces moyennes est l’erreur standard de la moyenne. On peut estimer l’erreur standard manuellement : \(ES = \frac{s}{\sqrt{n}}\). Finalement, on peut calculer les intervalles de confiance au niveau de 95 % : \(\bar{x} \pm 1,96 \cdot ES\).
library(tidyverse)
# Simulez une population :
set.seed(1)
pop = rnorm(n = 20000, mean = 5, sd = 5)
# Prélevez 100 échantillons de 50 observations chacun et calculer la moyenne :
set.seed(1)
moyennes = map_dbl(1:100, ~mean(sample(pop, size = 50)))
# Visualiser la distribution :
ggplot(data = tibble(x = moyennes), aes(x = x)) +
geom_histogram(color = "white",
bins = 8, binwidth = 0.2,
fill = "darkorange2") +
theme_minimal(base_size = 12) +
labs(x = "Distribution des moyennes",
y = NULL)
# Calculer l'écart type de « moyennes » :
sd(moyennes)[1] 0.6273012# Voilà : on vient de simuler le calcul manuel de l'erreur standard
# On peut l'estimer avec un seul échantillon aussi :
set.seed(1)
echant = sample(pop, size = 50)
sd(echant) / sqrt(50)[1] 0.6952616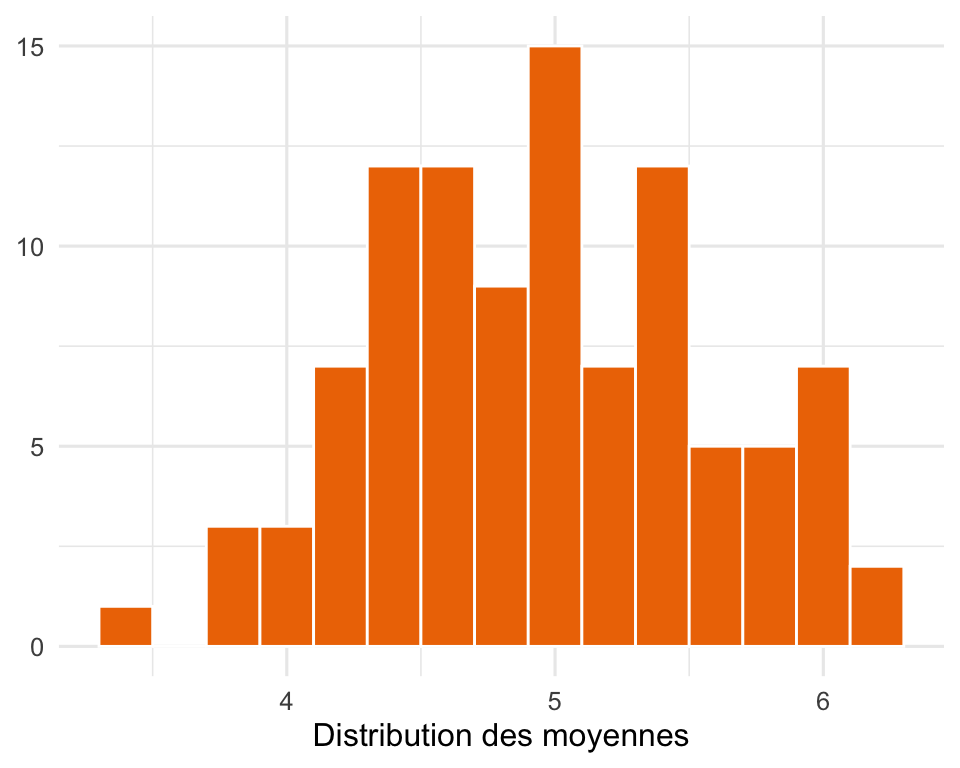
Consultez l’appli Standard Error ici pour examiner la relation entre la taille de l’échantillon et l’erreur standard.
On ne va jamais calculer la droite d’une régression manuellement, mais c’est utile de comprendre pourquoi une droite est la meilleure pour les données. La droite d’une régression linéaire lorsque la variable sur l’axe \(x\) est catégorielle sera toujours la droite entre la moyenne de la catégorie de référence (c’est-à-dire l’intercept) et la moyenne de la catégorie d’intérêt. La question, par contre, est comment calculer la droite lorsque la variable \(x\) est continue.
On commence avec le calcul de la moyenne des variables \(y\) et \(x\) :
\[\bar{x} = \frac{\sum\limits_{i=1}^{n}x_i}{n}\]
\[\bar{y} = \frac{\sum\limits_{i=1}^ny_i}{n}\]
Après, on peut calculer l’intercept et le slope :
\[\hat\beta_0 = \bar{y} - \hat\beta_1\bar{x}\]
\[\hat\beta_1 = \frac{\sum\limits_{i=1}^n(x_i - \bar{x})(y_i - \bar{y})}{\sum\limits_{i=1}^n(x_i - \bar{x})^2}\]
Simplement dit, la droite idéale sera cela qui minimise la distance entre chaque point dans la figure et elle-même. Consultez la simulation ici (trend line).
Les distances entre la droite et les observations réelles représentent tout ce que le modèle n’est pas capable d’expliquer (soit la variable prédictive numérique ou catégorielle). Il s’agit des résidus, représentés par \(\hat{e}\). On peut visualiser ces distances pour la Fig. 6.2 ci-dessus.