Code
sqrt(
sum((objet - moyenne)^2) / (length(objet)-1)
)Barnier (2023) (chap. 1–3; 5–7)
Ce chapitre se concentre sur des exercices de pratique pour vous familiariser avec R. Votre pratique maintenant sera essentielle pendant le cours : considérez ce temps-ci comme un investissement. Les exercices sont basés sur la lecture des chapitres de Barnier (2023).
Créez un script séparé pour les exercices de chaque chapitre. Par exemple, script_ch2.R serait le script où vous répondez à toutes les questions ci-dessous. C’est une façon simple d’avoir une structure organisée pour vos fichiers. Après, enregistrez ce script dans un dossier logique (vous pouvez créer un nouveau dossier pour vos scripts/réponses).
️ Question 1. Créez un nouveau script (script_1.R). Dans le script, créez un objet (vecteur) avec les nombres 5, 10, 15, 20, 25, 30, 35, 40, 45, 50.
️ Question 2. Créez un objet (vecteur) avec quelques mots (caractères). Vérifiez la classe de l’objet.
️ Question 3. Créez un objet avec des nombres et des mots. Quelle sera la classe de cet objet?
️ Question 4. Créez un objet, moyenne, avec la moyenne de l’objet créé ci-dessus (1). Faites la même chose pour l’écart-type et.
Explorons les concepts de variance et d’écart-type.
La formule de la variance d’échantillon :
\[ \text{Variance} = s^2 = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1} \]
Pour calculer manuellement la dispersion (c.-à-d. la variance) :
Heureusement, R nous donne une fonction pour automatiser ce calcul : la fonction var(). Testons-la avec nos exemples :
Finalement, on peut calculer l’écart type en prenant la racine carré de la variance.
La formule de l’écart-type d’échantillon :
\[ \text{Écart-type} = s = \sqrt{\frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1}} \]
sqrt(
sum((objet - moyenne)^2) / (length(objet)-1)
)Ou, plus simplement, on utilise la fonction sd().
sd(mesNombres)C’est très facile de calculer la variance et l’écart-type en R avec les fonctions de base : var() et sd(). Dans notre cours, on va utiliser l’écart-type fréquemment (il est plus intuitif que la variance).
# La variance d'un objet numérique
var(objet)
# L'écart-type d'un objet numérique
sd(objet)Traditionnellement, on utilise <- pour créer une variable en R. Ici, on utilise =, qui sert le même objectif. Bien que les deux soient acceptables, il y a une préférence pour <- dans le LSP (Language Syntax Protocol) du langage.
️ Question 5. Créez un vecteur langues avec les mots français, anglais, espagnol et allemand. Nommez-le langues.
️ Question 6. Exécuter la commande nchar(langues). Quelle est la réponse?
️ Question 7. Comment ordonner alphabétiquement les langues?
️ Question 8. Quelle sera la conséquence d’exécuter langues = sort(langues)?
Il est toujours important d’être cohérent. Nos variables auront fréquemment plus d’un mot, donc il faut décider comment combiner les mots de façon intuitive. Les deux façons les plus populaires de nommer nos variables sont cammelCase et snake_case.
Les tableaux sont les objets les plus importants (normalement). Bien que nous les importions à partir d’un fichier, il est possible de créer un tableau ici manuellement. Un tableau est simplement une collection des vecteurs (chaque colonne est un vecteur). C’est pourquoi il est important de bien connaître les vecteurs.
Il y a plusieurs types de tableaux : tibbles, data frames, data tables sont les plus importants. On va se concentrer sur les tibbles, qui peuvent être créées avec la fonction tibble() ou tribble(). Tapez ?tibble() et ?tribble() pour comprendre les différences entre elles. Il faut charger l’extension tidyverse pour utiliser ces fonctions (qui proviennent de l’extension tibble, incluse dans tidyverse).
Voici un exemple d’un tableau (tibble) en deux formats : large et long.
Il s’agit d’un tableau où plusieurs colonnes représentent une même variable. Ici, phonologie, syntaxe et phonetique pourraient être classé dans une même variable : cours. En plus, des tableaux larges contiennent plus d’une observation par ligne : ici, on voit trois notes par ligne.
#
library(tidyverse)
# Large
large = tribble(~id, ~phonologie, ~syntaxe, ~phonetique,
"PLK", 80, 55, 92,
"GP", 67, 79, 83,
"MFG", 72, 99, 90)
# La fonction tribble permet de créer manuellement un tableau ligne par ligne
large
#> # A tibble: 3 × 4
#> id phonologie syntaxe phonetique
#> <chr> <dbl> <dbl> <dbl>
#> 1 PLK 80 55 92
#> 2 GP 67 79 83
#> 3 MFG 72 99 90Dans le tableau long ci-dessous, chaque ligne représente une seule observation, et chaque colonne représente une seule variable. Ce type d’organisation de données est appelé tidy data en anglais. Notez que les contenus des deux tableaux ici sont identiques.
#
# Long
long = tribble(~id, ~cours, ~note,
"PLK", "phonologie", 80,
"PLK", "syntaxe", 55,
"PLK", "phonetique", 92,
"GP", "phonologie", 67,
"GP", "syntaxe", 79,
"GP", "phonetique", 83,
"MFG", "phonologie", 72,
"MFG", "syntaxe", 99,
"MFG", "phonetique", 90)
# Visualiser le tableau :
long
#> # A tibble: 9 × 3
#> id cours note
#> <chr> <chr> <dbl>
#> 1 PLK phonologie 80
#> 2 PLK syntaxe 55
#> 3 PLK phonetique 92
#> 4 GP phonologie 67
#> 5 GP syntaxe 79
#> 6 GP phonetique 83
#> 7 MFG phonologie 72
#> 8 MFG syntaxe 99
#> 9 MFG phonetique 90On utilise tidyverse (spécifiquement l’extension tidyr) pour transformer un tableau de large à long et vice-versa.
names_to : Le nom de la nouvelle colonne pour les noms des colonnes dans le tableau original (large)
values_to : Le nom de la nouvelle colonnes pour les valeurs (les notes ici)
cols : Quelles colonnes sont ciblées pour la transformation
#> # A tibble: 9 × 3
#> id cours note
#> <chr> <chr> <dbl>
#> 1 PLK phonologie 80
#> 2 PLK syntaxe 55
#> 3 PLK phonetique 92
#> 4 GP phonologie 67
#> 5 GP syntaxe 79
#> 6 GP phonetique 83
#> 7 MFG phonologie 72
#> 8 MFG syntaxe 99
#> 9 MFG phonetique 90Voici une figure de Wickham, Çetinkaya-Rundel, et Grolemund (2023) (chapitre 6) qui nous aide à visualiser ce genre de transformation :
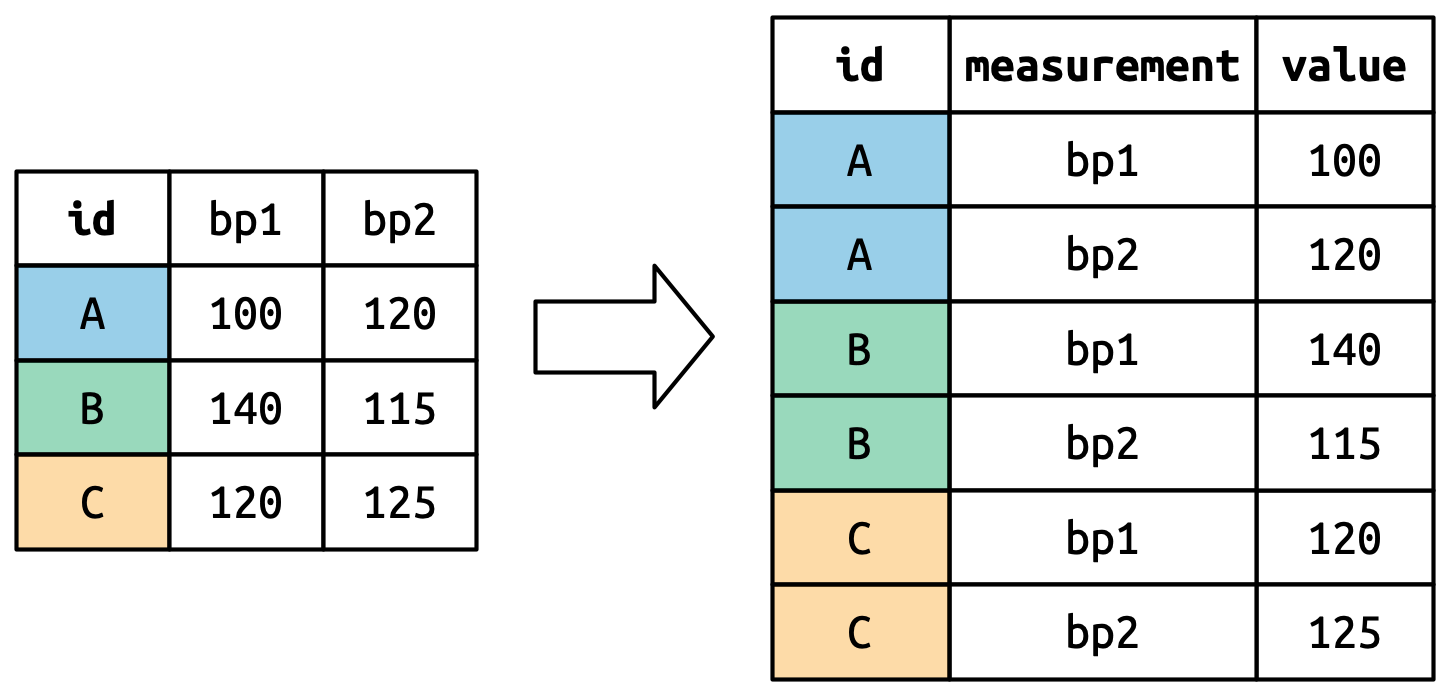
On peut aussi générer un tableau large à partir d’un tableau long.
#
long |>
pivot_wider(names_from = cours,
values_from = note)
#> # A tibble: 3 × 4
#> id phonologie syntaxe phonetique
#> <chr> <dbl> <dbl> <dbl>
#> 1 PLK 80 55 92
#> 2 GP 67 79 83
#> 3 MFG 72 99 90Quand on travaille avec plusieurs colonnes (soit le tableau large ou long), il est utile de transposer les données pour être capable de visualiser rapidement toutes les colonnes sur l’écran. On peut utiliser la fonction glimpse() :
#
glimpse(large)
#> Rows: 3
#> Columns: 4
#> $ id <chr> "PLK", "GP", "MFG"
#> $ phonologie <dbl> 80, 67, 72
#> $ syntaxe <dbl> 55, 79, 99
#> $ phonetique <dbl> 92, 83, 90
glimpse(long)
#> Rows: 9
#> Columns: 3
#> $ id <chr> "PLK", "PLK", "PLK", "GP", "GP", "GP", "MFG", "MFG", "MFG"
#> $ cours <chr> "phonologie", "syntaxe", "phonetique", "phonologie", "syntaxe", …
#> $ note <dbl> 80, 55, 92, 67, 79, 83, 72, 99, 90|> ou %>%
Le « pipe » (|>) permet de combiner plusieurs fonctions dans une ordre beaucoup plus intuitive. Le raccourci pour le « pipe » est {{< kbd Command+shift+M >}} (Mac) ou {{< kbd ctrl+shift+M >}} (Windows). Examiner le code ci-dessus pour comparer deux versions d’une même séquence de commandes. L’utilisation du « pipe » rend le code beaucoup plus facile à lire. Veuillez noter que |> est la version native de %>%, un autre « pipe » de l’extension magrittr, incluse dans tidyverse (consultez les diapos pour apprendre comment définir |> par défaut dans RStudio).
#
# Filtrer les donnes et créer une nouvelle colonne (note au carré) sans utiliser le « pipe » :
mutate(filter(long, note > 70), note_carre = note^2)
#> # A tibble: 7 × 4
#> id cours note note_carre
#> <chr> <chr> <dbl> <dbl>
#> 1 PLK phonologie 80 6400
#> 2 PLK phonetique 92 8464
#> 3 GP syntaxe 79 6241
#> 4 GP phonetique 83 6889
#> 5 MFG phonologie 72 5184
#> 6 MFG syntaxe 99 9801
#> 7 MFG phonetique 90 8100
# Avec le « pipe » :
long |>
filter(note > 70) |>
mutate(note_carre = note^2)
#> # A tibble: 7 × 4
#> id cours note note_carre
#> <chr> <chr> <dbl> <dbl>
#> 1 PLK phonologie 80 6400
#> 2 PLK phonetique 92 8464
#> 3 GP syntaxe 79 6241
#> 4 GP phonetique 83 6889
#> 5 MFG phonologie 72 5184
#> 6 MFG syntaxe 99 9801
#> 7 MFG phonetique 90 8100Question 9. Quel type de tableau est le meilleur pour l’analyse de données à vos avis…?
Question 10. Quel type est le plus pour les résultats des questionnaires à partir des sites tels que Google Forms ou MS Forms?
️ Question 11. Comment calculer la moyenne générale des notes? Et l’écart-type?
️ Question 12. Comment créer une nouvelle colonne qui calcule la distance entre les notes et 100?
️ Question 13. Comment filtrer seulement les notes supérieures à 70?
️ Question 14. Comment calculer la moyenne par cours?
Question 15. Importer le fichier sampleData.csv. Donnez-lui le nom donnees. Examinez les données attentivement pour comprendre leur structure.
Heureusement, RStudio vous aide à trouver des fichier si vous appuyez sur le Tab. Il est pourtant très utile de bien connaître la structure des fichiers dans notre projet. Si vous avez téléchargé les fichiers du cours comme indiqué, les chemins des fichiers seront plus faciles et logiques, étant données l’organisation de nos dossiers. Heureusement, RStudio effectue une recherche récursive dans les fichiers de votre projet. Donc, vous n’avez pas besoin d’ajouter donnees/mon_fichier.csv. Il suffit d’écrire mon_fichier.csv et Tab et RStudio listera le fichier même s’il est dans un dossier ou sous-dossier, ce qui sera très pratique dans notre cours!
Question 16. Les données sont-elles tidy? Autrement dit, le tableau est-il large ou long?
Question 17. Quelles sont les moyennes et les écarts-types des tests? Votre réponse doit inclure la fonction summarize().
Question 18. Les moyennes du groupe control sont-elles supérieures ou inférieures aux celles du groupe target?
Question 19. Commment ajouter une colonne qui contient la note au carré? Si vous utilisez Google ou ChatGPT, quel type de question posez-vous?
Question 20. Filtrez les données pour conserver seulement les étudiants dont les notes sont supérieures ou égales à 7.
tidyverseLes neuf extensions dans tidyverse sont très utiles pour les différents éléments de l’analyse de données. Dans la figure ci-dessous, vous pouvez observer le rôle de chaque extension dans un projet typique d’analyse quantitative. Dans notre cours, on utilisera spécialement readr pour importer des données; tidyr pour organiser des tableaux; dplyr pour transformer des variables; et ggplot2 pour visualiser des patrons pertinents.
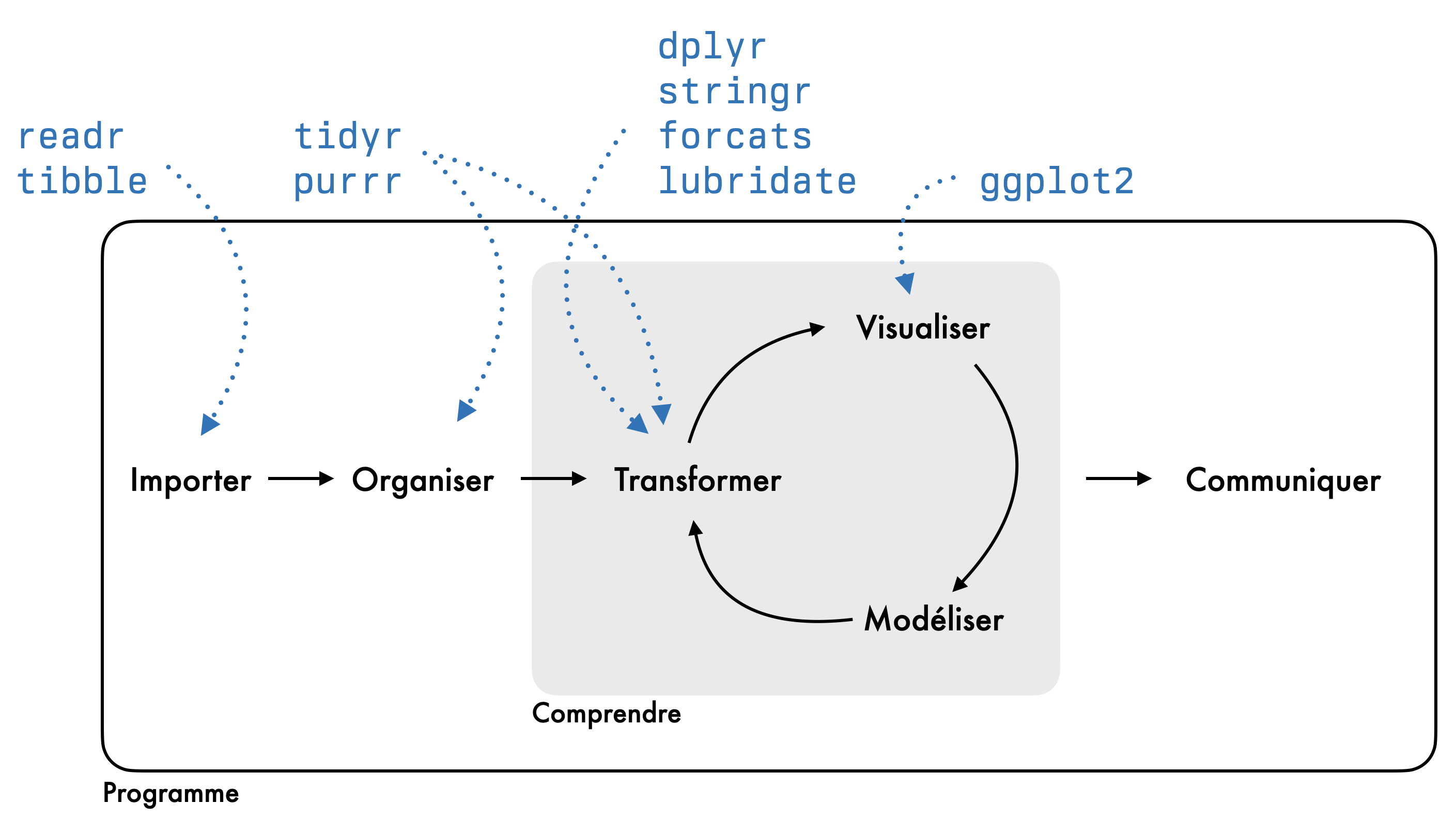
tidyverse utilisées dans une analyse de donées