| id | geo | langues | question | reponse | correct |
|---|---|---|---|---|---|
| 3 | Non | Non | quell... | le néerlandais | 0 |
| 3 | Non | Non | en_an... | le catalan | 1 |
| 3 | Non | Non | quell... | le swati et l'anglais | 0 |
| 3 | Non | Non | en_es... | le swati et l'anglais | 1 |
| 3 | Non | Non | quell... | le swati et l'anglais | 0 |
10 Nettoyage (b)
10.1 Nettoyage enchainé
Bien que la première partie de ce chapitre contienne un script pour nettoyer nos données, on a créé des étapes séparémment. On pourrait pourtant utiliser le pipe pour enchainer toutes nos opérations. Retournez au chapitre précédent et enchainez votre code en utilisant |>.
AvertissementLe bon ordre?
Il faut s’assurer que le vecteur cle et le tableau du questionnaire contiennent le même ordre de réponses avant de combiner les deux. Si les ordres sont différents, la méthode utilisée ici ne fonctionnera pas.
L’avantage d’enchaîner les opérations est clair : c’est beaucoup plus concis. Cependant, ces opérations sont moins transparentes, ce qui rend le code moins lisible. Ne croyez pas que j’ai écrit ce bloc de code d’un seul coup. Au contraire, j’ai exécuté le code au fur et à mesure que je le construisais, afin de pouvoir visualiser le tableau de données au fur et à mesure que je construisais le code. Vous pouvez faire la même chose : sélectionnez une partie du code (sans inclure le pipe à la fin) et l’exécutez. Ensuite, visualisez l’objet q_net pour vous familiariser avec le résultat (temporaire).
Voici le résultat que vous devez produire : les données sont nettoyées et prêtes pour l’analyse. On peut continuer avec les questions de l’exercice de pratique ci-dessous.
10.2 Questions d’interprétation
Voici les questions discutées en classe. Il est important de noter qu’il n’est pas possible d’y répondre sans avoir préalablement nettoyé les données. Même les systèmes d’intelligence artificielle ont des difficultés dans ce type de tâche.
Pratique
Question 1. Quelle est la précision moyenne en fonction de la variable langues?
Question 2. Quelle est la précision moyenne en fonction de la variable geo?
Question 3. Quelle est la précision moyenne des participants 4, 7, 14, 15 et 17 (ensemble)?
Question 4. Créez une nouvelle colonne qui classe les participants qui aiment la géographie et qui parlent d’autres langues vs les autres. La précision de ces deux groupes est-elle affectée par la nouvelle classification?
Question 5. Créez quelques figures pour explorer les patrons des données. Quelles figures sont appripriées étant donnée la classe de la variable de réponse? Consultez les commentaires ci-dessous.
Étant donné que la variable y est binaire, ce type de figure ne fonctionne pas. Ici, on ne voit que 4 points (il y en a plus, mais les points sont tous superposés). Même dans le cas où la variable x serait continue, le problème persisterait.
Peut-être envisagez-vous l’option geom_jitter(). Bien que cette option soit capable de minimiser le problème (en dispersant les points), elle ne le réglera pas étant donnée la classe de la variable y en question.
Ici, on observe le même type de problème. Bien que ce type de figure soit fréquemment recommandé (si la variable x est catégorielle), la variable y doit être continue. Notez que les médianes1 sont extrêmes ici (!).
Finalement, lorsqu’on utilise des points pour représenter la précision moyenne, on arrive à un graphique informatif. Toutefois, il faut noter qu’ici on n’examine pas les données brutes : on examine plutôt les moyennes (ce qui explique pourquoi la figure fonctionne).
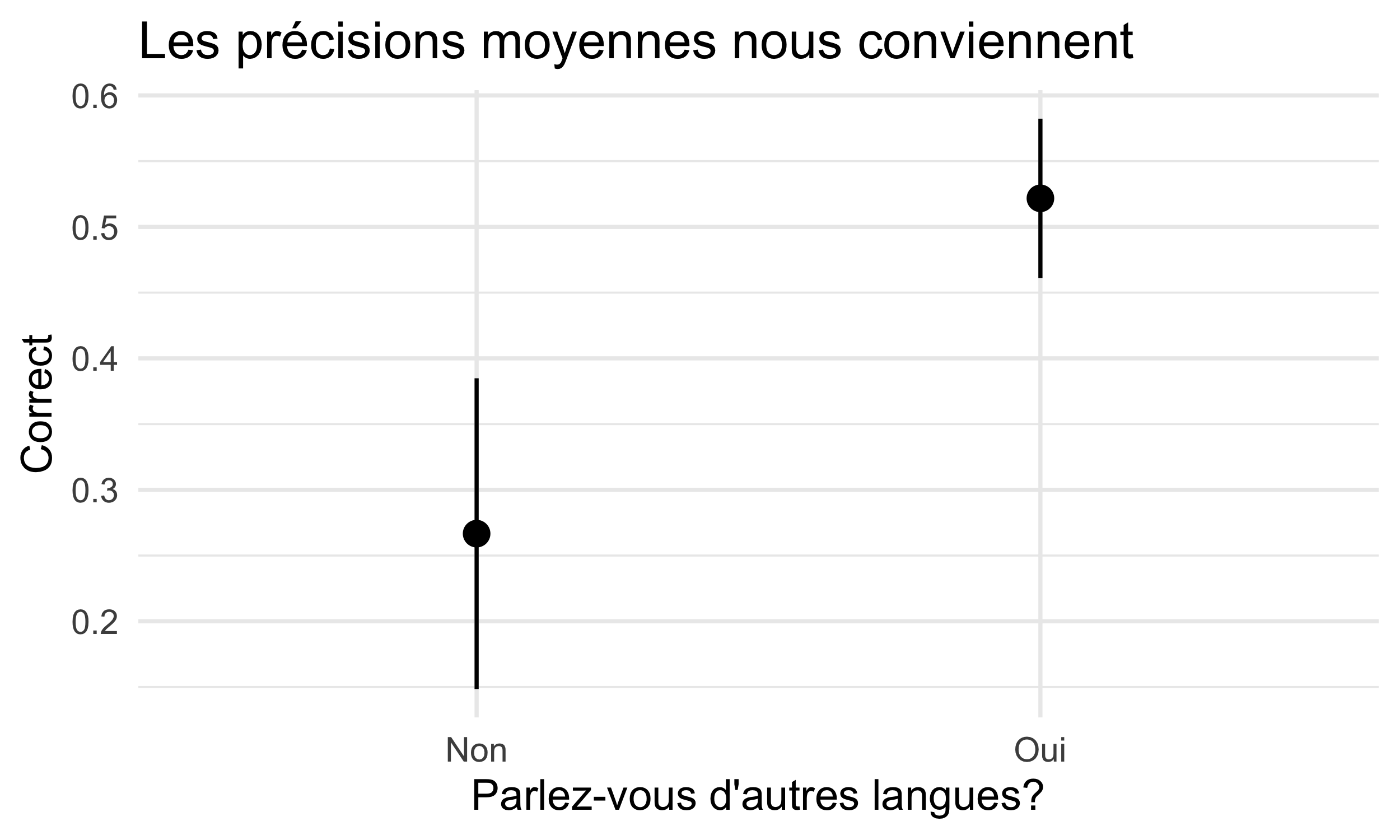
Dans les figures explorées ici, notez que :
- la variable
ysemble continue (0.00, …,1.00). Cependant, on sait qu’il s’agit d’une variable binaire. Il faudrait adapter la figure en conséquence (en transformant la classe de la variablecorrecten facteur avec la fonctionas_factor()); - dans la troisième figure (moyennes), l’axe
yreprésente un pourcentage. Donc, on pourrait adapter l’échelle utilisée. Plus tard, on va le faire à partir de l’extensionscales, qui nous permet de changer les échelles dans nos axes.
NoteRecoder les variables?
On peut facilement dichotomiser n’importe quelle variable catégorielle en utilisant la fonction if_else().2 Par exemple, dans le fichier villes.csv, dont la variable ville a trois niveaux (Calgary, Montréal, Québec), on pourrait ajouter une nouvelle variable binaire (c’est-à-dire dichotomisée) qui classe les villes en deux groupes : les villes dont le français est la langue officielle vs les villes où il n’est pas (Calgary). Cette nouvelle variable pourrait être appelée langue.3
Code
villes = read_csv("donnees/villes2.csv")
villes = villes |>
mutate(langue = if_else(ville == "Calgary",
"anglais",
"français"))
# Alternative moins concise :
# villes = villes |>
# mutate(langue = if_else(ville %in% c("Montréal", "Québec"),
# "français",
# "anglais"))| note | ville | duree | langue |
|---|---|---|---|
| 77.65000 | Montréal | 37 | français |
| 48.59063 | Calgary | 34 | anglais |
| 74.73000 | Québec | 38 | français |
| 64.67619 | Calgary | 21 | anglais |
| 65.69000 | Montréal | 36 | français |
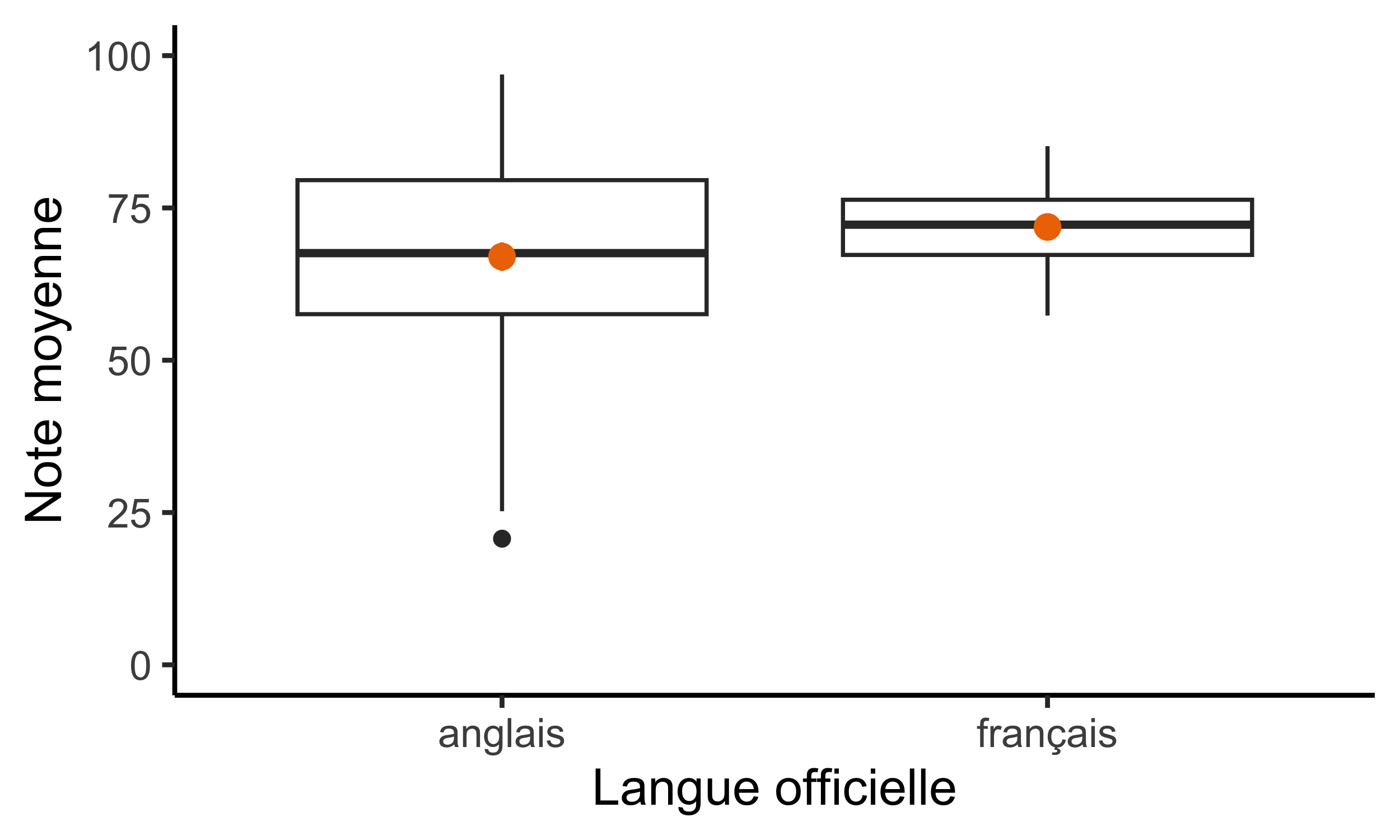
Finalement, la nouvelle colonne nous permet d’évaluer l’effet de la francophonie d’une ville sur la performance des apprenants du français au Canada dans nos données hypothétiques :
10.3 Combiner des scripts?
flowchart LR
A[Nettoyage] --> B[Exploration]
B --> C{Analyse}
On a révisé ci-dessus comment (a) nettoyer un fichier et (b) créer des graphiques. Vous pouvez certainement compléter (a) et (b) dans un même script. Par contre, comme discuté dans le chapitre 10, c’est toujours une bonne idée de séparer les différents éléments dans une analyse pour maximiser l’organisation de notre flux de travail.
Supposez que le nettoyage ci-dessus est dans un script appelé script_10_net.R. Dans ce script, un charge nos extensions et on importe notre fichier de données. Naturellement, on nettoie les données dans le même script. Ensuite, créez un script appelé script_10_exp.R pour ajouter les codes qui génèrent les graphiques discutés ci-dessus (ainsi que les tableaux pour les moyennes, etc.). Dans ce script, on peut simplement charger le script précédent :
Code
# Contenu du fichier script_10_vis.R
source("script_10_net.R")
# Exemple d'un des graphiques de la question 5 :
ggplot(data = q_net, aes(x = langues, y = correct)) +
stat_summary() +
labs(x = "Parlez-vous d'autres langues?",
y = "Correct",
title = "Les précisions moyennes
nous conviennent") +
theme_minimal()La fonction source() permet de charger le script, c’est-à-dire qu’elle va exécuter toutes les lignes de code dans le script. C’est une façon simple « d’enchaîner » des scripts différents pour séparer les éléments de notre analyse. En effet, on peut charger plusieurs scripts en même temps.4 Comme d’habitude, il faut toujours bien connaître la localisation de vos fichiers.
Valeur centrale d’un caractère séparant une population en deux parties égales (Antidote).↩︎
Cette fonction nous permet d’avoir plusieurs niveaux, naturellement, vu qu’on peut intégrer plusieurs
if_else()ensemble. Le résultat binaire n’est que l’option standard de la fonction.↩︎Effectivement, quand on utilise des modèles statistiques, les variables catégorielles sont automatiquement recodées en utilisant la méthode dummy coding, c’est-à-dire
0ou1. Si la variable contient trois niveaux (p. ex.,villeici), on aura deux nouvelle colonnes binaires (MontréaletQuébecici). Dans les données en question,Calgarysera automatiquement représentée par la combinaison0 0. Voilà pourquoi on interprète notre intercept ici représenteraitCalgary, vu qu’il s’agit de « la valeur prévue quand toutes les variables sont0».↩︎Avant de charger un script, il faut s’assurer qu’il fonctionne correctement!↩︎