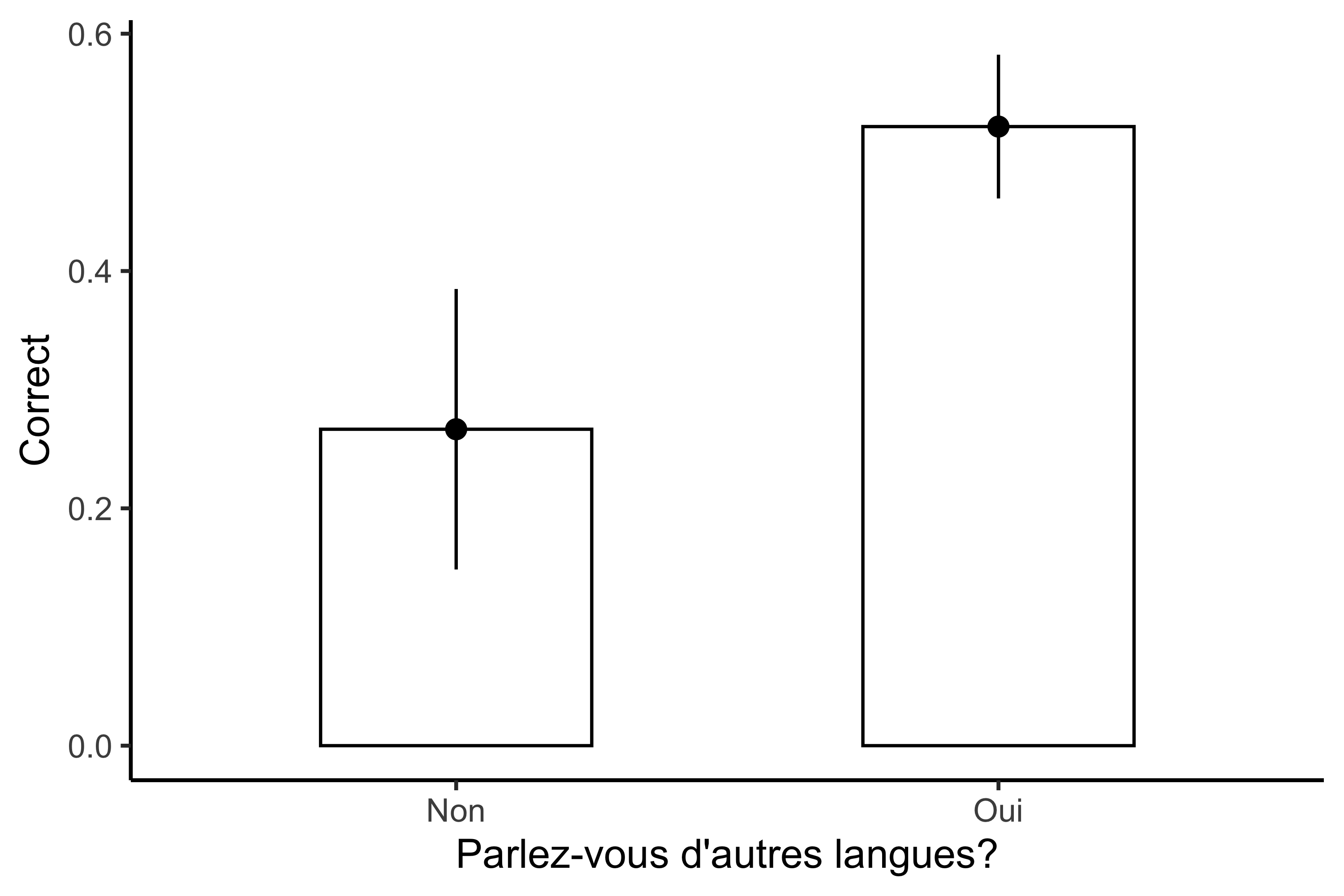
Voici la figure et le modèle du questionnaire 2 (déjà examinés). On avait vu que la précision entre les participants qui parlent d’autres langues et ceux qui ne les parlent pas semble être différente dans la figure. Autrement dit, les erreurs standard ne sont pas superposées.
Code
# On utilise ici le script déjà créé pour# nettoyer les données :source("Scripts/script_11_nettoyage.R")ggplot(data = long, aes(x = langues, y = correct)) +stat_summary(geom ="bar", fill =0.2, width =0.5, color ="black") +stat_summary() +theme_classic(base_size =13) +labs(y ="Correct",x ="Parlez-vous d'autres langues?")
Figure 12.1. L’influence de parler une autre langue sur la précision d’un questionnaire hypothétique (l’axe y représente la précision moyenne, pas la variable de réponse brute, qui est originalement binaire)
Notre modèle, par contre, n’est pas capable de rejeter l’hypothèse nulle par rapport à la variable langues (\(p = 0,082\)). Par conséquent, on ne peut pas conclure que le fait de parler une autre langue améliore les notes des participants dans le questionnaire en question.
Code
mod2 =glm(correct ~ langues, data = long, family ="binomial")library(sjPlot)tab_model(mod2, transform =NULL,string.pred ="Variables", string.ci ="IC 95 %",string.est ="Coefficients",string.p ="Valeur p")
correct
Variables
Coefficients
IC 95 %
Valeur p
(Intercept)
-1.01
-2.29 – 0.06
0.083
langues [Oui]
1.10
-0.08 – 2.46
0.082
Observations
84
R2 Tjur
0.038
N’oubliez pas que :
la fonction glm() doit contenir l’argument family = "binomial";
les coefficients sont toujours exprimés en log-odds (logs de cotes) quand on visualise le modèle avec summary();
on peut utiliser exp() pour extraire les cotes des log-odds;
on évite l’utilisation des probabilités pour les effets d’un coefficient individuel, car la courbe de probabilité n’est pas constante;
la fonction predict() est extrêmement utile pour prévoir des réponses à partir des nouvelles données en utilisant un modèle (soit la régression linéaire ou logistique).
NoteTableau de conversion
Voici un tableau adapté à partir de Garcia (2021) (p. 146) pour faciliter la conversion entre les unités discutées en classe. L’hypothèse nulle = \(\hat\beta = 0\), ce qui équivaut intuitivement à une probabilité de 50 %.
P
Odds
ln(odds) = \(\hat\beta\)
0.10
0.11
–2.20
0.20
0.25
–1.39
0.30
0.43
–0.85
0.40
0.67
–0.41
0.50
1.00
0.00
0.60
1.50
0.41
0.70
2.33
0.85
0.80
4.00
1.39
0.90
9.00
2.20
Pratique
Question 1.Le temps de réaction. Chargez rClauseData.csv (propositions relatives en anglais) et répondez aux questions suivantes :
Enlevez les éléments de remplissage (fillers) et changez les classes des variables selon le besoin.
Examinez les temps de réaction entre les deux groupes linguistiques (figure)
Explorez et rapportez deux modèles : une régression linéaire et une régression logistique
Question 2.Le rôle de la pause. Maintenant, on va examiner le rôle de la prosodie (la présence d’une pause #) dans l’interprétation des pronoms rélatifs :
Mary saw the daughter of the nurse who likes to dance (NoBreak)
Mary saw the daughter # of the nurse who likes to dance (High)
Mary saw the daughter of the nurse #who likes to dance (Low)
Lisez les trois phrases ci-dessus et considérez qui est la personne représentée par who. La proposition relative se réfère à quelle phrase nominale (PN) :
the daughter (high attachment)
the nurse (low attachment)
L’interprétation dépend de quelle langue on examine. En anglais, low attachment est typiquement l’option préférée (donc, the nurse ici). En espagnol, par contre, l’option typique est high attachment (donc, the daughter ici). La question à examiner ici est si la présence d’une pause peut changer la préférence défaut d’un participant dont la langue maternelle est l’anglais ou l’espagnol.
Examinez les réponses des deux groupes en fonction des conditions considérées dans les données. Créez un graphique.
Rapportez les résultats d’une régression logistique
Question 3 (difficile).La rétroaction. Maintenant, on va (ré)examiner le fichier feedbackData.csv :
Chargez le fichier feedbackData.csv
Est-ce qu’on peut prévoir la rétroaction à partir de la note dans la tâche A? Si oui, quelle est la probabilité qu’un participant soit dans le groupe Recast si sa note est de 90?
12.2 Un aperçu de notre cours
Révisons les objectifs de LNG-1100, détaillés sur monPortail :
Important
Formuler et tester des hypothèses de recherche [en linguistique]
Se familiariser avec les éléments de base de l’analyse de données quantitatives
Interpréter et synthétiser des résultats statistiques dans un rapport scientifique
Tous nos objectifs sont concentrés dans nos questionnaires et dans les deux problèmes du cours, où vous devez compléter une analyse de données complète. Donc, pendant le cours, vous avez :
importé des fichiers de données en format csv;
nettoyé des fichiers générés à partir des sondages du Microsoft Forms (Questionnaire 3) et du Google Forms (Questionnaire 4);
exploré des patrons pertinents en utilisant des tableaux résumés ainsi que des graphiques appropriés, effectuant les transformations nécessaires;1
exécuté et interprété des modèles statistiques (linéaire et logistique);
communiqué vos résultats dans un rapport scientifique/académique en format PDF, dans lequel vous avez géré vos références bibliographiques en utilisant un fichier .bib;
développé des compétences en gestion de fichiers afin d’optimiser votre flux de travail.
Les étapes énumérées ci-dessus combinent l’analyse de données quantitatives, la composition de documents académiques et la gestion bibliographique — tout cela à partir d’un seul outil : RStudio. Même si vous n’utilisez pas des données quantitatives dans un projet, vous pouvez facilement le développer en utilisant Quarto. Donc, pour vos cours futurs dans le bac, vous pouvez facilement continuer à utiliser RStudio ainsi que votre bibliothèque de références.
12.3 Les concepts les plus importants
Voici une liste de concepts statistiques discutés en classe pendant le cours.
AstuceLes concepts de base
Valeur\(p\) : la probabilité de trouver des données en question étant donné l’hypothèse nulle
Si l’hypothèse nulle est vraie et on la rejette \(\rightarrow\) erreur de type I. Autrement dit, notre effet n’est pas réel, mais notre valeur \(p\) est significatif
Si l’hypothèse nulle est fausse et on ne la rejette pas \(\rightarrow\) erreur de type II. Autrement dit, notre effet est réel, mais notre valeur \(p\) n’est pas significatif (la puissance statistique.))
Le problème : on ne sait jamais si \(H_0\) est vraie
Intervalle de confiance : si on répétait la même expérience \(n\) fois, la valeur réelle serait dans l’intervalle en question 95 % du temps (mais l’intervalle serait différent pour chaque échantillon!). Simplement dit, l’intervalle de confiance à 95 % vous dit que la moyenne de la population est dans cet intervalle avec une probabilité de 95 % (pas trop intuitif!)
Hypothèse nulle : notre point de départ. On n’a que deux options : rejeter l’hypothèse nulle OU ne pas rejeter l’hypothèse nulle. On ne l’accepte jamais! Autrement dit, on ne peut pas prouver l’absence d’un effet, logiquement.2
Si on n’examine qu’un groupe, \(H_0 : \mu = 0\) (la moyenne est de zéro)
Si on compare les moyennes de deux groupes, a et b, \(H_0 : \mu_a = \mu_b\) (il n’y a pas de différence entre les deux moyennes; autrement dit, les deux groupes/échantillons viennent de la même population)
Si on examine des coefficients d’un modèle, \(H_0 : \beta = 0\).
Intercept (\(\beta_0\)) : la valeur prévue par le modèle lorsque toutes les autres variables sont 0
Slope (\(\beta_n\)) : l’effet d’une variable prédictive
Log-odds : l’unité standard pour les coefficients d’une régression logistique3
Transformation wide-to-long : processus fréquemment nécessaire si notre tableau n’est pas tidy, c’est-à-dire s’il contient plus d’une observation par ligne et/ou plus d’une colonne par variable d’intérêt
Lorsqu’on utilise un modèle simple, on veut mesurer l’effet d’une variable prédictive sur une variable de réponse. Normalement, on examine plusieurs variables prédictives en même temps (c.-à-d. un modèle multiple).
Dans une régression linéaire :
vérifiez si la variable de réponse est plus ou moins normale/gaussienne;
interprétez l’intercept seulement si cette interprétation est utile dans votre analyse (normalement, elle n’est pas);
les coefficients utilisent toujours les mêmes unités utilisées par les variables dans le modèle;
on peut utiliser la fonction predict() pour prévoir des réponses à partir du modèle.
Dans une régression logistique :
les coefficients sont listés en log-odds lorsque vous utilisez summary() pour imprimer les résultats;
on évite une interprétation d’un coefficient individuel à partir des probabilités : on utilise log-odds ou odds;
si vous voulez parler des probabilités, on peut utiliser la fonction predict(..., type = "response") pour prévoir des réponses à partir du modèle. C’est une bonne idée de visualiser les prévisions dans une figure (page supplémentaire de la séance 13).
12.4 Problème B
Notre premier problème du cours (Problème A) a produit un document PDF. Vous serez donc à l’aise avec la structure nécessaire pour notre dernier problème. La révision qui suit se concentre sur les méthodes statistiques utilisées dans le cours, dont certaines seront essentielles pour vos évaluations finales.
Pratique finale
Question 1. Dans une étude examinant les effets d’une méthode fantastique d’enseignement sur la performance des étudiants, les chercheurs ont exécuté une M avec X groupes d’apprenants. Les scores de performance des étudiants ont été analysés pour déterminer s’il y avait des différences significatives entre les groupes à la fin de l’étude. Les résultats étaient les suivants : F(2, 57) = 4,32, p < 0,038. Répondez aux questions suivantes :
Combien de groupes X étaient considérés dans l’étude?
La performance des participants a été calculée à partir d’un questionnaire. Combien de questions ce questionnaire comportait-il?
Quelles sont l’hypothèse nulle et l’hypothèse alternative de l’étude?
Quelle méthode statistique M a été employée?
Pouvons-nous rejeter l’hypothèse nulle?
Si nous rejetons l’hypothèse nulle, pouvons-nous déterminer à partir des informations données où se situent les différences parmi les méthodes d’enseignement considérées?
Supposons que l’objectif de l’étude est de quantifier l’efficacité de la méthode d’enseignement mentionnée. Quel est d’après vous le principal problème de l’étude?
Question 2. Observez le tableau ci-dessous et rapportez les résultats de l’analyse. Combien de niveaux les facteurs A–B comportent-t-ils? Combien d’observations totales avons-nous dans l’analyse?
Source de variation
Somme des carrés
Degrés de liberté
Moyenne des carrés
F
p
Facteur A
6.068
2
3.034
9.073
0.000253
Facteur B
5.122
1
5.122
15.316
0.000174
Residuals
30.765
92
0.334
Question 3. Observez le tableau ci-dessus encore une fois. Vous vous souvenez quelle est la relation entre les valeurs dans les colonnes Somme des carrés, …, F? Comment pouvons-nous dériver les valeur F des autres colonnes?
Question 4. Téléchargez le fichier phonetique.RData. Le format RData offre plusieurs avantages. Importez-le en utilisant la fonction load(). Vérifiez les classes des variables : qu’est-ce que vous notez? Il s’agit d’une étude sur l’acquisition de contrastes vocaliques en français à partir de trois groupes de participants (trois langues maternelles). Les apprenants ont étudié le français pendant une période de six mois. Les groupes ont été séparés en deux conditions (deux méthodes d’enseignement) : la condition traditionelle, où les séances n’avaient pas d’information explicite sur la phonétique du français, et la condition phonétique, où les séances avaient un élément dédié à la phonétique du français. Avant de commencer l’expérience, tous les participants on fait un test de français qui se concentrait sur l’identification des voyelles dans la langue. Après la période de six mois, un autre test a été fait. Les scores de chaque test sont dans les données. Explorez le fichier en question et répondez aux questions suivantes.
Créer une figure qui résume les patrons dans les données.
Modélisez les données et rapportez les résultats. La méthode d’enseignement a-t-elle un effet sur l’apprentissage des contrastes vocaliques?
Question 5. Voici les coefficients d’un modèle statistique. Vous pouvez peut-être deviner quelles sont les données modélisées ici. Les valeurs ont été arrondies à trois chiffres (donc les valeurs p ne sont pas vraiment zéro). Les données décrivent les passagers à bord du Titanic. Le modèle analyse la survie de ces passagers étant données trois variables, à savoir, la classe, le sexe, et l’âge (dichotomisé : enfant vs adulte) de chaque passager. Observez le résultat ci-dessous et répondez aux questions suivantes :
Vous devez savoir déjà quel type de modèle on utilise ici, étant donnée l’information ci-dessus. Si nos données sont dans un objet nommé Titanic, quelle serait la formule pour exécuter le modèle en question? Vous pouvez télécharger les données à partir du dépôt Git du cours.
Quelle était la probabilité de survie à la catastrophe si vous étiez un homme dans la deuxième classe? Et d’une femme dans la même classe?
Considérant les types de passagers analysés ici, quelle était le meilleure scénario possible? Calculez la probabilité de survie pour chaque combinaison possible de passager.
Garcia, Guilherme Duarte. 2021. Data visualization and analysis in second language research. New York, NY: Routledge.
Par exemple, une colonne incorrect/correct vers 0/1 pour qu’on puisse calculer la précision des participants, c’est-à-dire la proportion des réponses correctes par opposition aux réponses incorrectes.↩︎
J’ai mentionné en classe que la statistique bayésienne nous permet de confirmer un effet nul. Dans notre cours, cependant, on utilise la statistique traditionnelle (fréquentiste).↩︎
Notez que la fonction sjPlot::tab_model() affiche les odds par défaut; consultez les dernières pages supplémentaires.↩︎